Senior Experience Machine Learning Section 7 - Support Vector Regression
| Support Vector Regression is a type of Support Vector Machine. And a Support Vector Machine creates a “separation of classes”. it draws a line here, that’s what it does. --> SVR is a SVM supporting linear and nonlinear regression |  |
|---|
Instead of trying to fit the largest possible street between two classes while limiting margin violations, SVR tries to fit as many instances as possible on the street while limiting margin violations. mmm okay
The width of the street is controlled by a hyper parameter Epsilon ε.
| SVR performs linear regression in a higher dimension. Each piece of data is a dimension. (don't try to think of it visually lol think of it like the 3blue1brown video from KAM with the sliders except there’s a lot of data points there) |  |
|---|
One thing is that this doesn’t make predictions well, it partitions groups and ends up with constraints
apparently we want to create a “street” that can contain as many points as possible, with the street width being 2ε technically.
Kernel - functions that change the form of data
What type of Kernel?
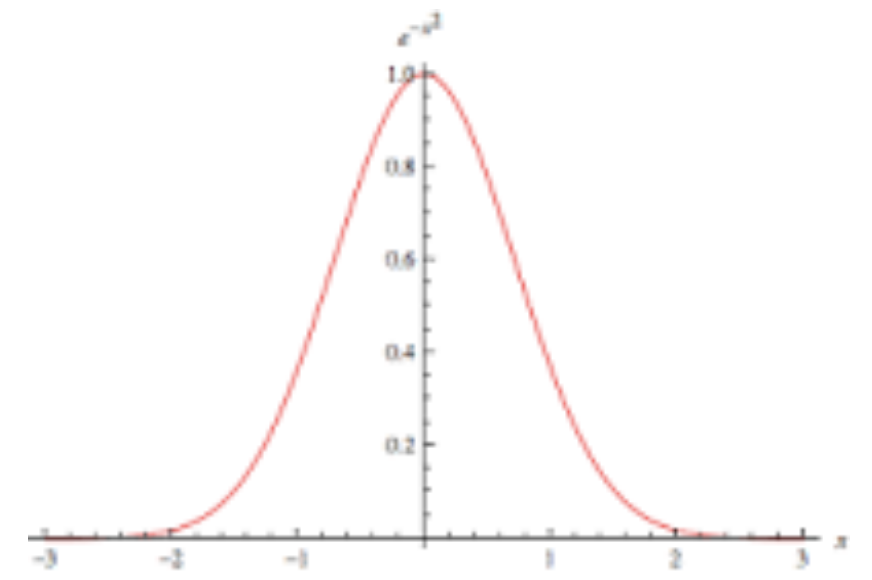
Gaussian (bell curve)
| Regularization - gets rid of overfitting, prevents wild fluctuations in the dataset | 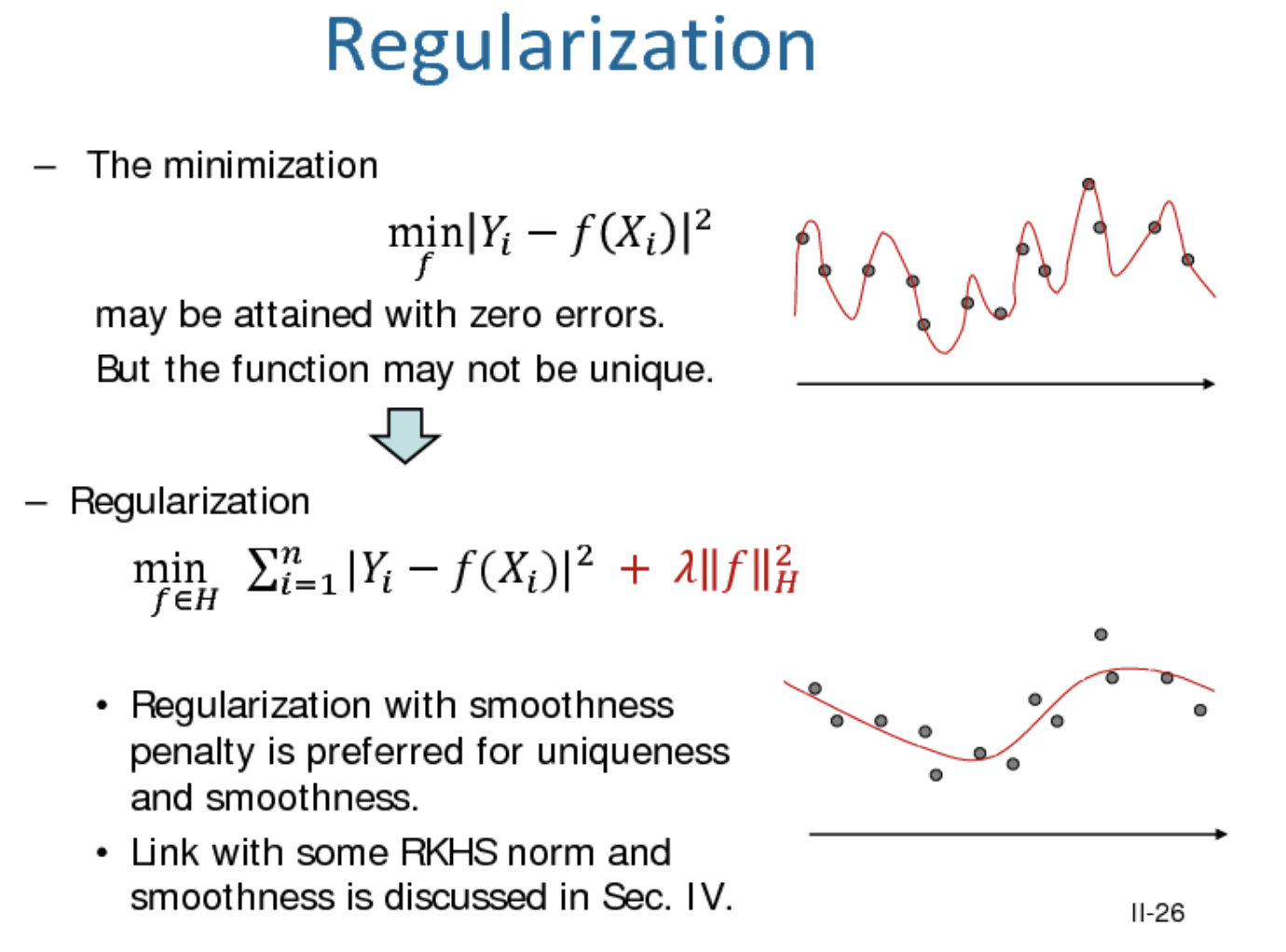 |
|---|
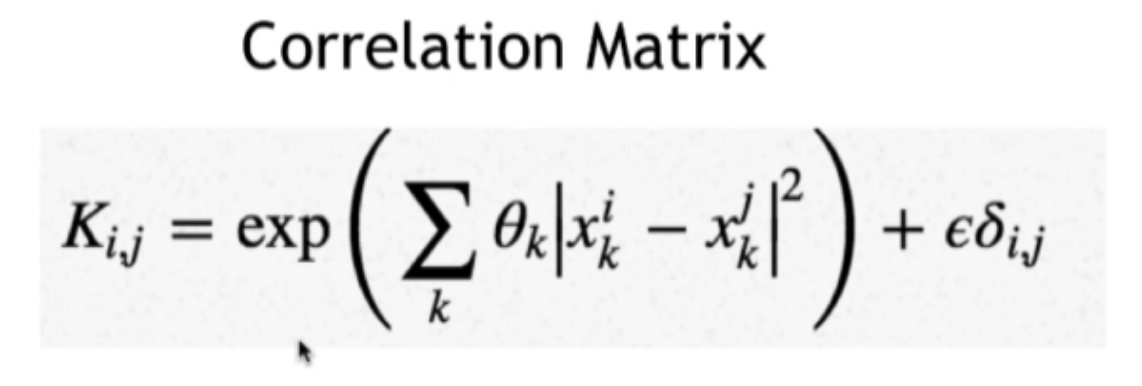 | This is where the kernel gets evaluated. Also it seems like it’s the kernels job to map lower dimensional data to higher dimensional data? |
|---|
Ka=yad , where
K = correlation matrix
a = set of unknowns to solve for
y = vector of values that correspond to the training set
The inverse of K and y are used to solve for a, a=K^-1*y
Creation of the Regressor:
Will not work without feature scaling the data, just returns a horizontal line.
(Why is y lowercase and X uppercase always, is it just a dependent-independent variable thing?)
(leaf data is a linear problem, so it should use the kernel = linear, but for swishy_swooshy data kernel = poly or kernel = rbf (gaussian) work)
However, without feature scaling, only a flat horizontal line is returned
for the machine learning models we’ve been using, feature scaling was actually built in. For kernel = linear, feature scaling is taken care of
However SVR doesn’t seem to apply feature scaling, so we need to do that first
Feat. Scaling:
We’re creating 2 objects, x and y, from standard scale class
The metrics of features X and y will be scaled
Using fit transfer method from scx and scy object
And also transforming due to fit_transform component
But not doing any work between a training and test set like last time
Results:
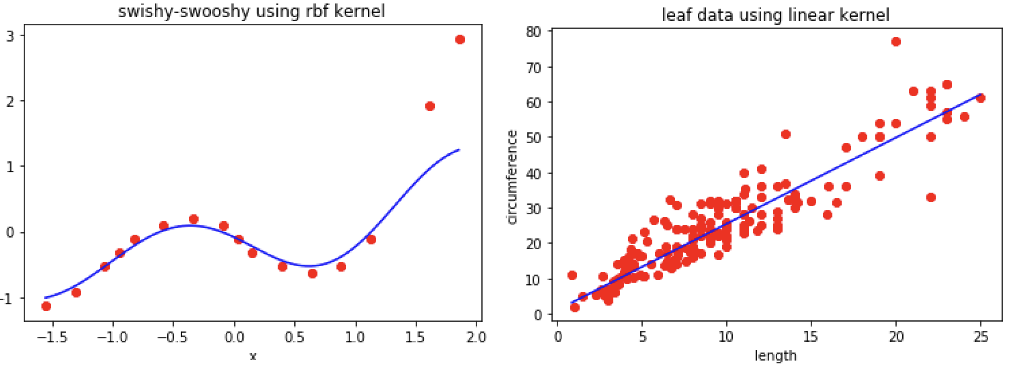
Regularization led the model to believe the top 2 points were outliers, so the graph doesn’t go all the way to the top.
So this is OK for predicting values in the well fitted area, which would be from -1.0 to 1.0.
(is regularization impacted by both x and y axis?)
